
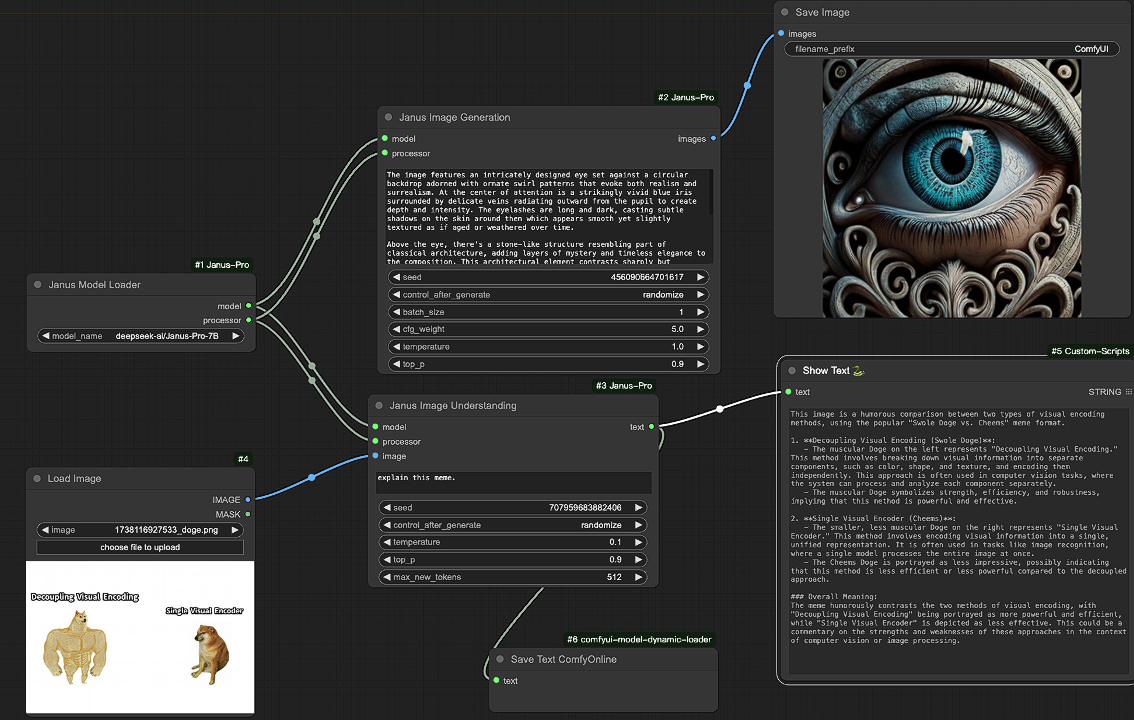
Youu can using MS_Diffusion in ComfyUI
-- MS-Diffusion origin From: MS-Diffusion
NEW Update
- 2024/09/06:fix runway error/load single controlnet now /首次加载不再需要连外网。
Previous updates
- del clip repo,Add comfyUI clip_vision loader/加入comfyUI的clip vision节点,不再使用 clip repo。
1.Installation
In the ./ComfyUI /custom_node directory, run the following:
git clone https://github.com/smthemex/ComfyUI_MS_Diffusion.git
2.requirements
pip install -r requirements.txt
缺啥装啥。
If the module is missing, please pip install
3 Need model
Need download "ms_adapter.bin" : link
clip vision model ( any base from CLIP-ViT-bigG-14-laion2B-39B-b160k)
Control_img image preprocessing, please use other nodes
├── ComfyUI/models/checkpoints/
| ├── any SDXL weigth
├── ComfyUI/models/photomaker/
| ├── ms_adapter.bin
├── ComfyUI/models/clip_vision/
| ├── clip_vision_g.safetensors or CLIP-ViT-bigG-14-laion2B-39B-b160k.safetensors
├── ComfyUI/models/controlnet
| ├──any SDXL controlnet
4 using tips
--生成物体名称需要用[ ]括起来,有多少个物体,就要有多少张图片输入;
--To generate object names, they need to be enclosed in [ ]. As many objects as there are, there must be as many images to input;
5 Example
normal 2 boject 常规双主体图生图 最新示例。

normal 4 boject 4主体图生图。更多的主体没有测试,旧示例,仅供参考。

2 object zero shot and controlnet img2img 双物体加controlnet引导 图生图,旧示例,仅供参考


6 Citation
MS-Diffusion
@misc{wang2024msdiffusion,
title={MS-Diffusion: Multi-subject Zero-shot Image Personalization with Layout Guidance},
author={X. Wang and Siming Fu and Qihan Huang and Wanggui He and Hao Jiang},
year={2024},
eprint={2406.07209},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
IP-Adapter
@article{ye2023ip-adapter,
title={IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models},
author={Ye, Hu and Zhang, Jun and Liu, Sibo and Han, Xiao and Yang, Wei},
booktitle={arXiv preprint arxiv:2308.06721},
year={2023}
}