

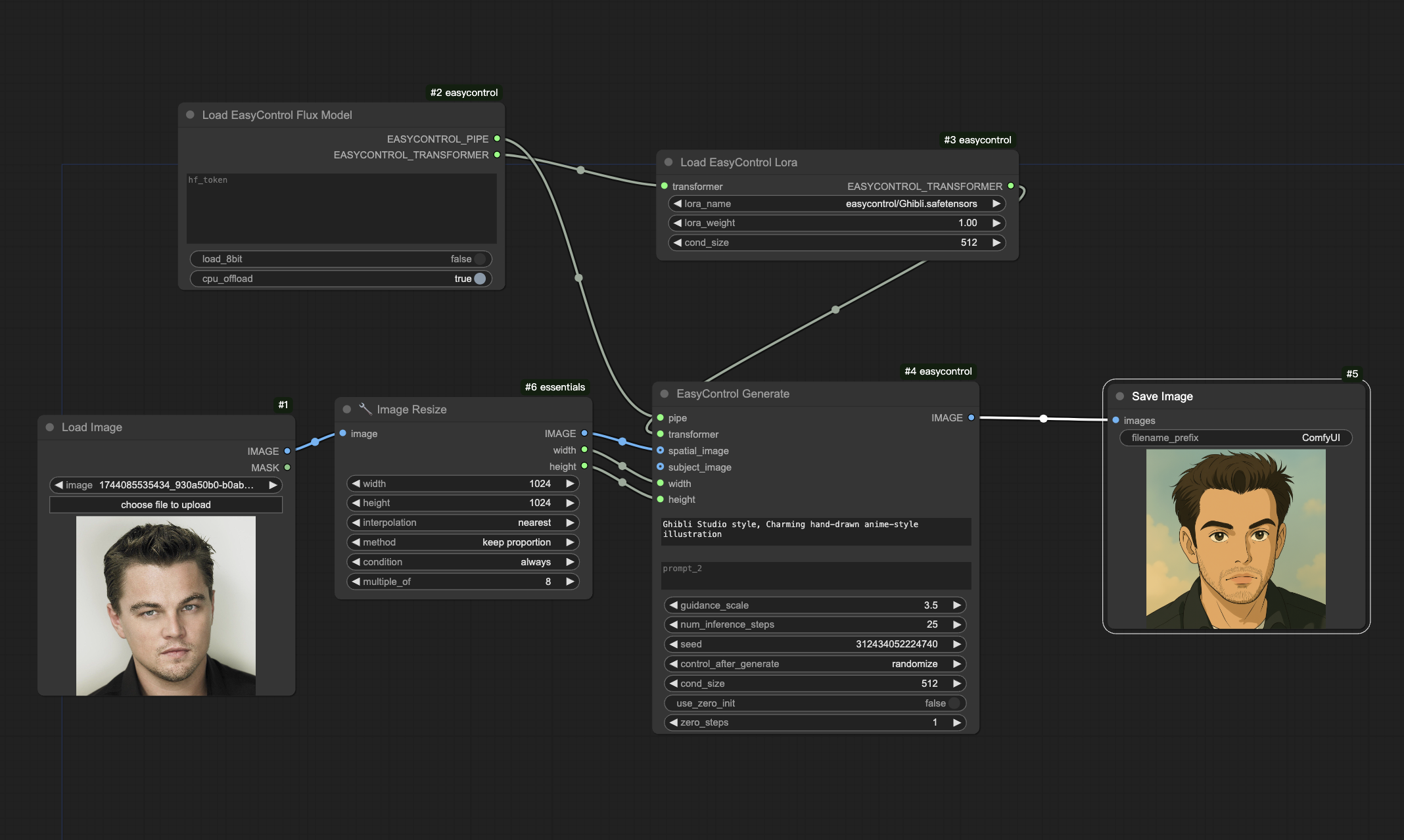
ComfyUI EasyControl Nodes: Unleash the Beast Within Your Images!
Ready to bend reality to your will? ComfyUI EasyControl Nodes are here to give you the reins of your ComfyUI image creations using the power of EasyControl!
[Check out the GitHub Repo!](https://github.com/Xiaojiu-z/EasyControl comfyui)
Warning: This ain't for the faint of heart (or those with puny GPUs). You'll need a whopping 40GB of VRAM to run this bad boy. (But hey, you can sneak by with only 24GB if you offload to the CPU. Just sayin'.)
Bonus: It'll automatically grab the Flux model for you (but make sure you've got 50GB of disk space ready to rumble!)
Pro-Tip: LORAs? Gotta stash 'em in the 'models/loras' directory.
Need LORA Inspiration? Peep this list: EasyControl LORA Lineup
EasyControl Deconstructed: It's Like Magic, But With Math!
EasyControl: The Zen Master of Diffusion Transformers
We've come a long way, baby! AI image generation is no longer a toddler scribbling on a wall. We've got masterpieces emerging from the digital ether, thanks to diffusion models like DALL-E, Stable Diffusion, and the Transformer titans: Google Imagen, Alibaba's AnyText, Tsinghua's PixArt-α, and the ultra-slick Flux.1.
But just cranking out pretty pictures isn't enough. We need control! We want to puppeteer poses, trace outlines, and sculpt the very depth of our scenes.
Enter Stable Diffusion, the UNet-based champ. ControlNet [83] showed up and dropped the mic with spatial conditional control – adding a trainable adapter network while keeping the original model's mojo. Then came IP-Adapter [80], letting us wrangle subject content like a boss.
But now we're riding the wave of Diffusion Transformers (DiT), like Flux.1 [29] and SD3 [9]. These DiTs are lean, mean, and scalable. But how do we move our control powers over? Existing DiT control methods can be a computational nightmare (Transformer's attention mechanism is a quadratic beast!), juggling multiple conditions is a recipe for disaster, and they play as well with community models as cats play with water.
That's where the paper "EasyControl: Adding Efficient and Flexible Control for Diffusion Transformer" [This Paper] comes in swinging. It's a novel, efficient, and flexible framework that gives us unified conditional control for DiT models. BOOM!
Why ControlNet Might Stumble in the DiT Era
Before we dive into EasyControl, let's give ControlNet a little love tap – and point out where it might struggle with these new DiTs:
- Architectural Face-Off: ControlNet was built for UNets. It copies the UNet encoder and injects conditional features into the UNet decoder. This doesn't translate well to the pure Transformer architecture of DiTs. It's like trying to fit a square peg in a round transformer-hole.
- Computational Cost: ControlNet is a hefty piece of kit (often as big as the base model itself – we're talking ~1B-3B parameters for SD1.5 ControlNet). During inference, you're running two massive networks, which is computationally expensive. Adding a similar behemoth adapter network to DiTs would just make things worse.
- Compatibility Conundrums: ControlNet, bless its heart, sometimes throws a hissy fit when combined with community fine-tuned models or LoRAs. It's like trying to get toddlers to share toys.
- Resolution Woes: ControlNet's way of handling condition maps can lead to information loss or weakened control if the input condition resolution is vastly different from the generation resolution. It's like trying to read a map that's been zoomed in too far.
EasyControl: The Secret Sauce
EasyControl is slicker than a greased watermelon, and it tackles these challenges head-on by leveraging the DiT architecture. It's got three key innovations that make it efficient, flexible, and totally plug-and-play:
-
Lightweight Condition Injection LoRA Module (CIL):
- Isolation is Key: EasyControl's core philosophy is "leave the main model alone!" It avoids messing with the DiT backbone that handles text and noise. Instead, it introduces an independent "Condition Branch" for the conditional signal (like a Canny edge map or a face image).
- LoRA with a Laser Focus: This ain't your grandma's LoRA. It doesn't fine-tune the model's backbone. Instead, it applies LoRA (Low-Rank Adaptation) exclusively within this new condition branch, learning how to encode and align the conditional information. The original text and noise branches? They're completely frozen. Like statues in a museum.
- The Perks: This design is packed with benefits:
- Light as a Feather: Each condition control module has a teeny parameter count (around 15M in the paper), which is much smaller than ControlNet.
- Plug-and-Play Perfection: Since the backbone network remains untouched, EasyControl modules can be easily loaded like plugins and coexist harmoniously with customized base models or style LoRAs, minimizing conflicts. No more model meltdowns!
- Zero-Shot Multi-Condition Sorcery: Get this: even though each condition module is trained independently, the framework can combine multiple different types of conditions (like pose + face) in a zero-shot manner for complex control, achieving stable results. It's like conducting an orchestra where everyone knows their part, even if they've never played together before! This is ensured by the subsequent Causal Mutual Attention mechanism.
-
Position-Aware Training Paradigm (PATP):
- Training on a Budget: To keep training costs down, EasyControl downsamples the input condition images to a fixed low resolution (like 512x512) during training.
- Cross-Resolution Kung Fu: So how can it accurately control high-resolution generation after training on low-resolution images? EasyControl uses Position-Aware Interpolation (PAI). For spatially strong conditions (like Canny, Depth), it intelligently interpolates the position embeddings based on the scaling factor between the original and resized condition maps. This ensures that even when the model sees a low-resolution condition, it understands the correct spatial location of its features in the final high-resolution output. It's like having a GPS for your image! For subject conditions (like Face), a simpler PE Offset strategy is used for distinction.
- Flexibility Unleashed: PATP lets EasyControl generate images at arbitrary resolutions and aspect ratios while maintaining good conditional control. It breaks the chains of fixed resolutions!
-
Causal Attention & KV Cache:
- Speed Boost: The computational bottleneck in Transformers is Self-Attention. EasyControl uses Causal Attention mechanisms (with different masking strategies for training and inference), which decouples the computation of the condition branch from the denoising timestep.
- KV Cache Magic: Based on this, EasyControl implements the first successfully applied KV Cache strategy in conditional diffusion models. At the beginning of inference (t=0), the system calculates and caches the Key and Value pairs generated by all condition branches once. In all subsequent denoising steps (t≥1), these cached values are directly reused, avoiding massive redundant computations. This significantly reduces inference latency, especially noticeable with a higher number of sampling steps. According to the paper, the full EasyControl is 58% (single-condition) to 75% (dual-condition) faster than the version without PATP and KV Cache. It's like having a turbocharger for your image generation!
EasyControl vs. ControlNet: A Showdown!
| Feature | EasyControl | ControlNet (Traditional Representative) | | :------------------ | :------------------------------------------------ | :----------------------------------------------- | | Base Architecture | Diffusion Transformer (DiT / Flux) | UNet (e.g., Stable Diffusion) | | Control Mechanism | Independent Condition Branch + Targeted LoRA (CIL) | Copied UNet Encoder + Zero Convolution Injection | | Parameter Count | Lightweight (~15M per condition) | Heavyweight (Comparable to base model, Billions) | | Inference Efficiency| High (Significantly reduced latency via KV Cache) | Lower (Requires running two large networks) | | Resolution Handling| Flexible (PATP+PAI supports arbitrary res/AR) | Relatively fixed, performance may drop with large res changes | | Multi-Cond Combo | Supports Zero-Shot stable combination | May require joint training, conflict prone, poor zero-shot | | Modularity/Compat.| High (Isolated, Plug-and-play, LoRA compatible) | Medium (May conflict with UNet tuning/LoRA) | | Training Method | Can train conditions independently | Usually single-condition; multi needs special design/joint training |
The Verdict
EasyControl is the first truly efficient, flexible, and plug-and-play unified control framework for Diffusion Transformers. It solves the core technical challenges of DiT control while keeping the parameter count and computational cost super low. Its zero-shot multi-condition combination skills and compatibility with community models are a game-changer for controllable generation within the DiT ecosystem.
Sure, the paper admits there are limitations with conflicting inputs and extreme resolutions, but EasyControl is a huge leap forward. It paves the way for more powerful and user-friendly controllable image generation models and marks a significant milestone in the evolution of DiTs.
So go forth and conquer! EasyControl awaits!
