
![[Guide] Training Hunyuan Video LoRA](https://cdn.sanity.io/images/zm7buxx5/production/14f81c7311e969df6a2d7d38de5829f2f4166a77-512x512.png?rect=0,112,512,289&w=550&h=310)
[Guide] Training Hunyuan Video LoRA
After Hunyuan Video started supporting LoRA, the community actively began exploring LoRA training. Currently, over 80 LoRA models have been created. On ComfyOnline, after introducing LoRA training, users have collectively trained more than 70 LoRA models, with a single user training up to 12 LoRA models. This guide will explain in detail how to train a Hunyuan Video LoRA on ComfyOnline. The dataset preparation steps described here are also applicable to training Hunyuan Video LoRA on any platform.
Preparing the Dataset
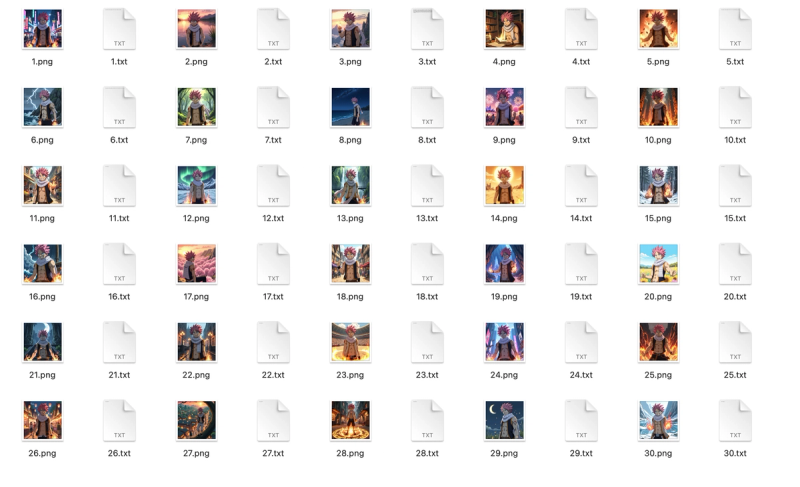
Image Dataset:
- Image Resolution
The aspect ratio of each image should not exceed 2. The optimal resolutions are 512 x 512, 512 x 768, or 768 x 512.
- Number of Images
Use 20 to 40 images for training.
Caption Dataset:
Each caption file should have the same name as its corresponding image file. For example:
1.png corresponds to the caption 1.txt.
File Content:
Describe the image. For example, if you are training a character LoRA, exclude details you don’t want the LoRA to learn. For instance, if all the characters have red hair and you don’t want to include “red hair” in prompts when using the LoRA, omit any mention of red hair in the caption files. The LoRA will automatically learn that the character has red hair, and no explicit prompt is needed to generate red-haired characters.
Example: Description for the following image:

Natsu_Dragneel staat op straat, handen vol vlammen.
Since this is a character LoRA, the caption avoids describing the character explicitly and instead focuses on the environment. Including details about clothing would also be beneficial here.
Note: Even if you include some details about the character in the captions, it is not a problem. You can add the same descriptions when using the LoRA, and it will still work fine.
Compress the Files into a ZIP Archive
Prepare the image and caption files, then compress them into a single ZIP file.
Starting the Training Process
enter train page:
https://www.comfyonline.app/explore/app/hunyuan-video-lora-train
Upload the Dataset
Upload the prepared ZIP file.
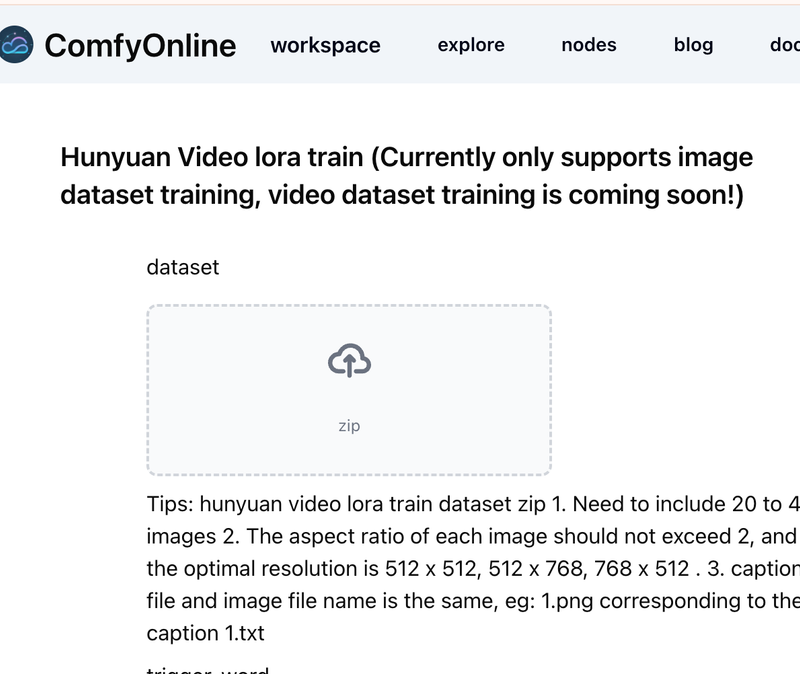
Enter a Trigger Word

Provide a unique trigger word that will activate the LoRA. This trigger word will automatically be added to the caption files. If the caption already includes the trigger word as a prefix, it will not be added again.
Wait for Training to Complete
Wait approximately one hour for the training to complete.
Once done, you’ll find the model_id and LoRA file on the right-hand side. You can download the LoRA file for local use or upload it to platforms like Hugging Face or Civitai.
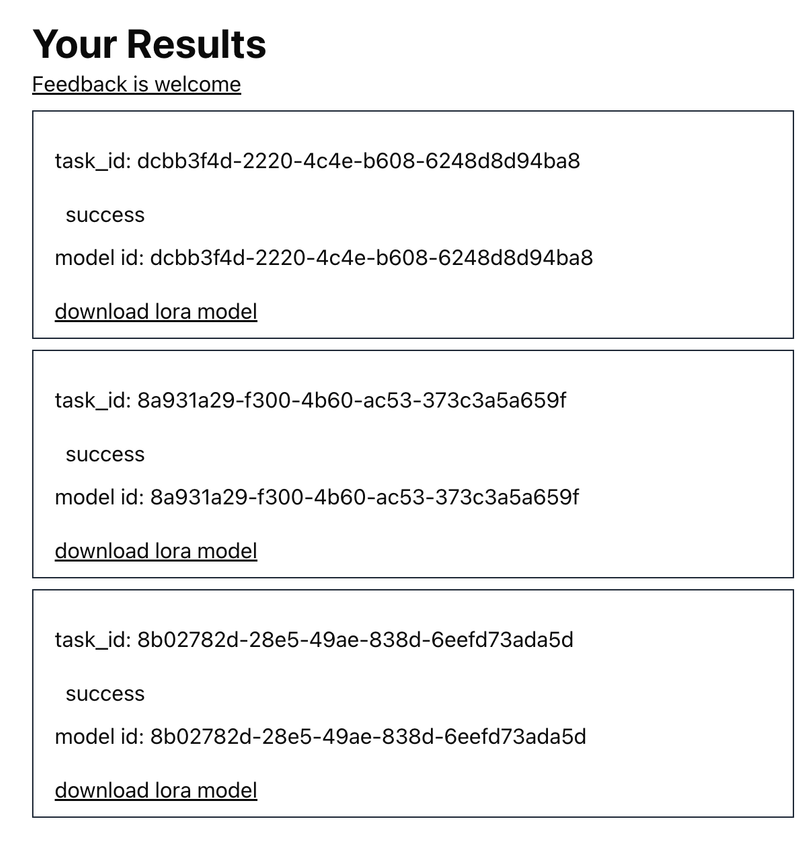
Using the Trained LoRA
- Upload to Hugging Face
- Upload to Civitai
- Use Directly with ComfyOnline model_id
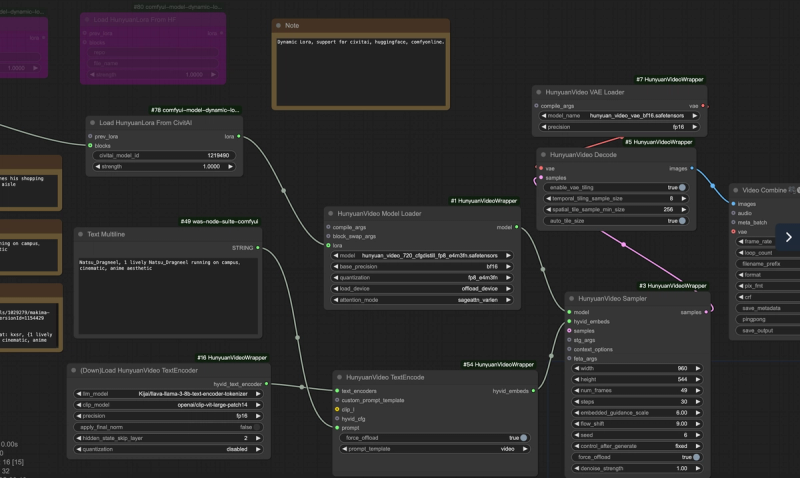
For more details, refer to:
ComfyOnline Dynamic LoRA in Workflow
With this workflow, you can create amazing videos. Start training your own Hunyuan Video LoRA today!